ai/qwen3-coder-next
Efficient 80B MoE coding model with 3B activated params, 256K context, and agentic capabilities
50K+
ai/qwen3-coder-next repository overview
Qwen3-Coder-Next
Qwen3-Coder-Next is an open-weight language model designed specifically for coding agents and local development. This innovative model features a Mixture-of-Experts (MoE) architecture that achieves remarkable efficiency with only 3B activated parameters out of 80B total parameters, delivering performance comparable to models with 10–20x more active parameters.
The model excels at advanced agentic capabilities including long-horizon reasoning, complex tool usage, and recovery from execution failures, making it highly robust for dynamic coding tasks. With its 256K context length and adaptability to various scaffold templates, Qwen3-Coder-Next seamlessly integrates with different CLI/IDE platforms such as Claude Code, Qwen Code, Qoder, Kilo, Trae, and Cline, supporting diverse development environments. This makes it highly cost-effective for agent deployment while maintaining exceptional performance across various coding benchmarks.
Characteristics
| Attribute | Value |
|---|---|
| Provider | Alibaba Cloud (Qwen Team) |
| Architecture | Qwen3Next (Hybrid: Gated DeltaNet + Gated Attention + Mixture of Experts) |
| Total Parameters | 80B |
| Activated Parameters | 3B |
| Context Length | 262,144 tokens |
| Input modalities | Text |
| Output modalities | Text |
| License | Apache 2.0 |
Using this model with Docker Model Runner
docker model run qwen3-coder-next
For more information, check out the Docker Model Runner docs.
Architecture Details
Qwen3-Coder-Next uses a sophisticated hybrid architecture with the following specifications:
- Layers: 48 layers with hybrid layout: 12 × (3 × (Gated DeltaNet → MoE) → 1 × (Gated Attention → MoE))
- Hidden Dimension: 2048
- Gated Attention: 16 Q heads, 2 KV heads, 256 head dimension
- Gated DeltaNet: 32 V heads, 16 QK heads, 128 head dimension
- Mixture of Experts: 512 total experts, 10 activated experts per token, 1 shared expert
- Training: Pretraining & Post-training stages
Benchmarks
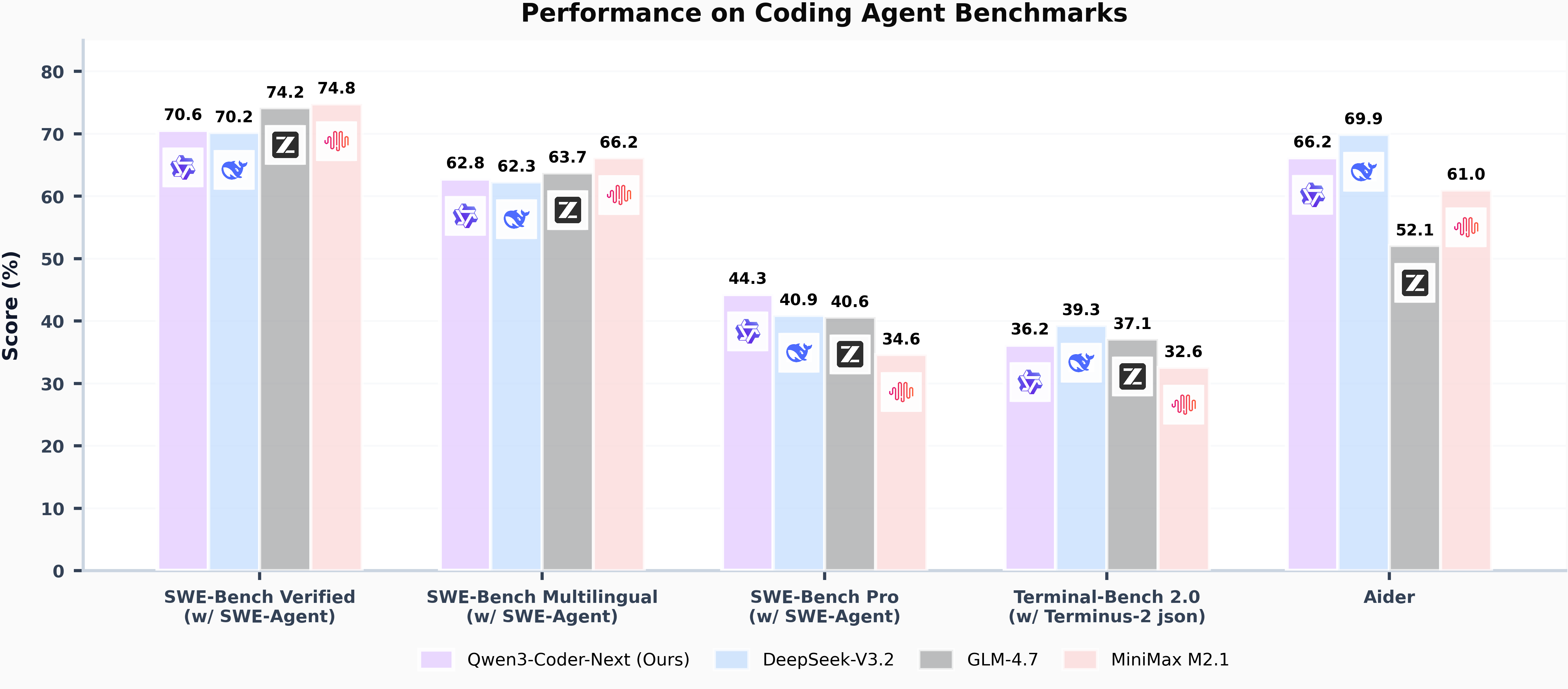
The model demonstrates strong performance across various coding benchmarks, achieving results comparable to much larger models while using significantly fewer activated parameters.
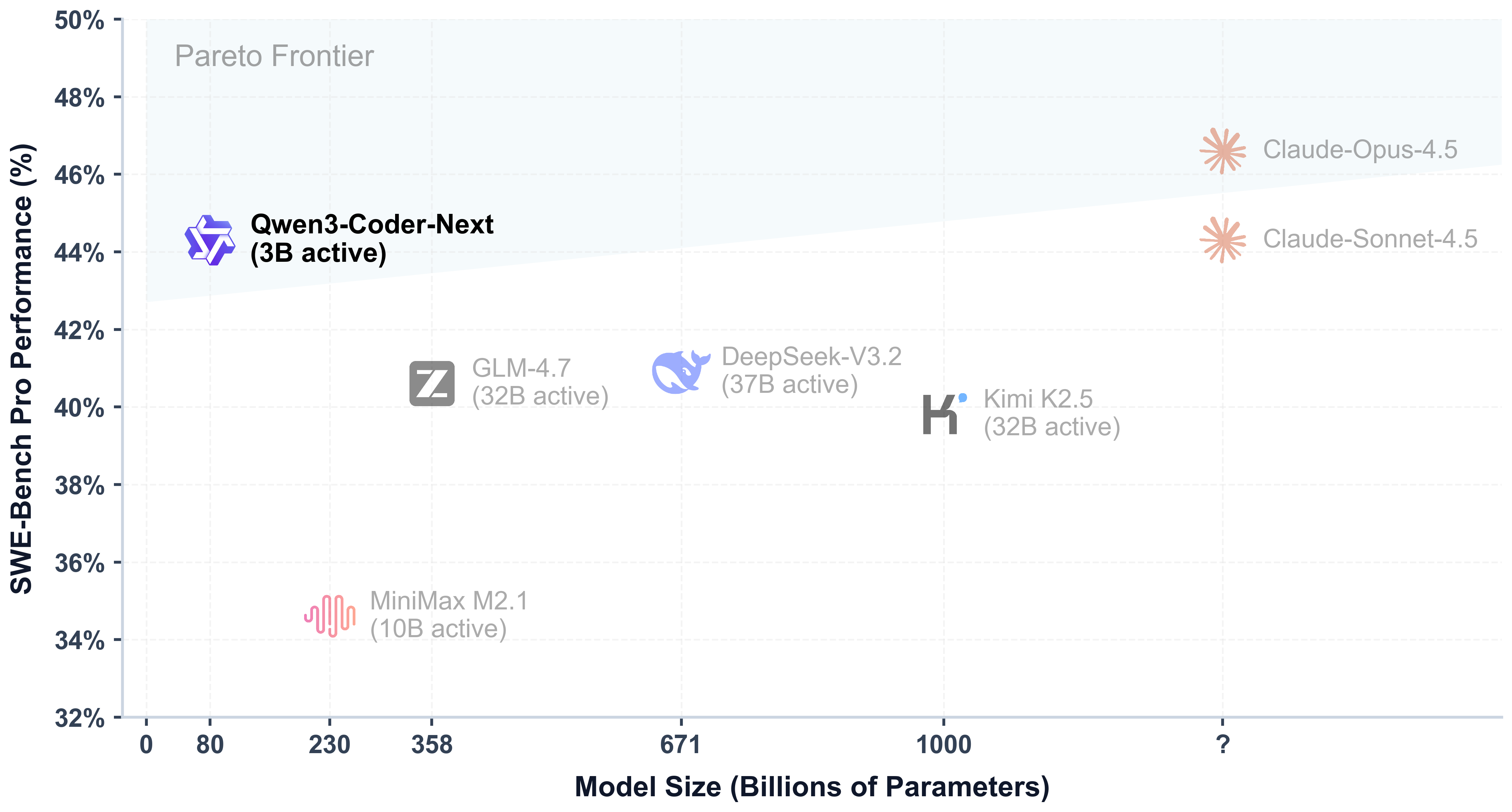
Qwen3-Coder-Next shows excellent performance on SWE-bench PRO, demonstrating its capability for real-world software engineering tasks.
Key Features
- Efficient Architecture: Only 3B parameters activated per token out of 80B total, making it highly efficient for deployment
- Long Context: Native support for 262K tokens, enabling handling of large codebases and extensive documentation
- Agentic Capabilities: Excels at tool calling, long-horizon reasoning, and error recovery
- IDE Integration: Seamless integration with various development environments and coding platforms
- Non-thinking Mode: Focuses on direct output without generating intermediate reasoning blocks
Links
- Qwen3-Coder-Next GGUF Repository
- Qwen3-Coder-Next Blog Post
- Original Model Repository
- GitHub Repository
- Documentation
Considerations
- Memory Requirements: It is recommended to have >45GB unified memory or RAM/VRAM to run 4-bit quantized versions
- Optimal Quantization: For best results, use any 2-bit XL quant or above (requires >30GB unified memory/combined RAM + VRAM)
- Context Length: Default context length is 256K tokens. If you encounter out-of-memory issues or server startup failures, consider reducing the context length to a shorter value such as 32,768 tokens
- Sampling Parameters: For optimal performance, use
temperature=1.0,top_p=0.95,top_k=40 - Model Updates: As of February 4, 2025, llama.cpp fixed a bug that caused Qwen to loop and have poor outputs. Ensure you're using the latest version of llama.cpp and updated GGUFs for improved outputs
- Inference Engines: The model is supported by various inference engines including SGLang (≥v0.5.8) and vLLM (≥0.15.0), as well as local tools like Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers
Generated by
This model card was automatically generated using cagent-action. Want to learn more about Docker Model Runner? Check out the project repository: https://github.com/docker/model-runner.
Tag summary
Content type
Model
Digest
sha256:cef2728a7…
Size
45.1 GB
Last updated
4 months ago
docker model pull ai/qwen3-coder-nextThis week's pulls
Pulls:
2,121
Jun 1 to Jun 7